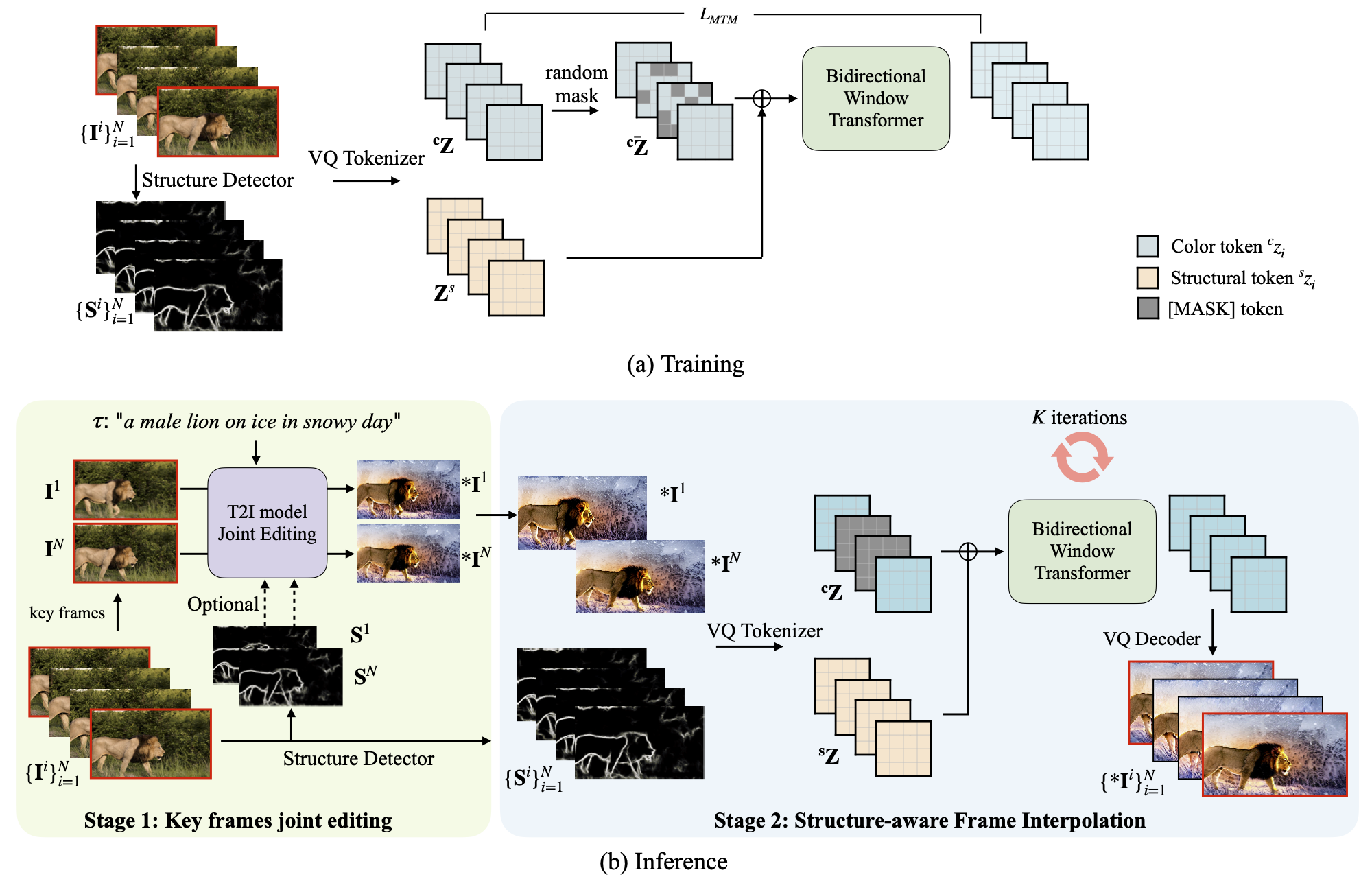
Method
We propose to disentangle the text-based video editing into a two stage pipeline, that involves keyframes joint editing using existing image diffusion model and structure-aware frame interpolation with masked generative transformers trained on video only datasets.
We propose MaskINT to perform structure-aware frame interpolation, which is the pioneer work that explicitly introduces structure control into non-autoregressive generative transformers.
Experimental results demonstrate that our method achieves comparable performance with diffusion methods in terms of temporal consistency and alignment with text prompts, while providing 5-7 times faster inference times.